Todas las pruebas pasan en staging. El lanzamiento sale el viernes. El lunes, un webhook de pago ha descartado silenciosamente una parte de los pedidos, el refresco de OAuth falló para las sesiones que permanecieron abiertas durante el fin de semana, y la API del socio devuelve HTTP 200 con "status":"failed" enterrado en el cuerpo. El informe de QA sigue marcando verde.
Este patrón se repite en todos los stacks e industrias. Las verificaciones funcionales pasan de forma aislada, y la producción cuenta una historia diferente. El informe de Splunk y Cisco Costos Ocultos del Tiempo de Inactividad 2026 sitúa la pérdida anual promedio por empresa del Global 2000 en 300 millones de dólares, con los fallos de aplicación e infraestructura impulsando aproximadamente un cuarto de todos los eventos de tiempo de inactividad.
Las pruebas funcionales de aplicaciones web para sistemas integrados es una disciplina propia. Tratarlas como una lista de clics en la interfaz ignora dónde viven los fallos reales. Los cinco patrones descritos aquí son los que aparecen con más frecuencia en las auditorías, junto con los casos de prueba que los detectan.
Por qué los errores de integración se escapan del QA
Las integraciones fallan en producción por razones que no tienen nada que ver con pruebas descuidadas. Fallan porque el entorno de prueba es estructuralmente diferente de la producción, y la mayoría de los procesos de QA no están diseñados para exponer esa brecha.
El staging cuenta una cómoda mentira. Las APIs de sandbox responden en 100 a 200 ms; los webhooks de producción bajo carga máxima pueden tardar de dos a cinco segundos. Los tokens de sandbox nunca expiran a mitad del flujo. Los servidores mock siempre devuelven el esquema contra el que se escribió la prueba. Los límites de tasa no colisionan porque no hay ninguna otra función en ejecución. Cada una de estas brechas es la semilla de un futuro incidente en producción.
Luego está la definición de hecho. La mayoría de las funcionalidades se lanzan en el momento en que pasan las pruebas unitarias y el flujo de la interfaz en el camino feliz. El flujo conectado, donde la funcionalidad habla con un proveedor cuyo comportamiento nadie controla, rara vez forma parte de los criterios de aceptación. El Informe sobre el Estado de la API 2025 de Postman, basado en una encuesta a más de 5.700 desarrolladores, descubrió que el 93% de los equipos de API todavía se topan con bloqueos de colaboración y documentación, y solo el 24% diseña APIs pensando en consumidores no humanos. Esa brecha se traduce directamente en errores de producción que el plan de pruebas nunca fue diseñado para detectar. Un proceso de pruebas funcionales disciplinado cierra la brecha al tratar los límites de integración como superficies de prueba por derecho propio.
Los cinco patrones de fallo de integración que vemos en auditorías
Los mismos patrones se repiten en las auditorías independientemente del stack o la industria. Cada uno es invisible para los planes de prueba estándar y muy visible para los usuarios finales. Así es como se ve cada uno y qué lo detecta a través de las pruebas funcionales para aplicaciones web.

Fallos en webhooks
Los webhooks fallan de maneras que las pruebas mock nunca reproducen. Se entregan dos veces, fuera de orden o directamente no se entregan. A veces el endpoint receptor devuelve 200, la cola marca el evento como procesado y la lógica de negocio silenciosamente nunca se ejecutó. ShipEngine, por ejemplo, permite solo 10 segundos para el reconocimiento y dos intentos de reenvío a intervalos de 30 minutos antes de que el evento se descarte completamente del despacho. Si el manejador es lento una vez, el evento desaparece.
Casos de prueba funcionales a añadir en el límite del webhook:
- Verificación de firma con cabeceras HMAC válidas, inválidas y ausentes.
- Manejo de reproducción y entrega duplicada con la misma clave de idempotencia.
- Entrega fuera de orden: procesar el evento B antes del evento A y verificar el estado correcto.
- Tolerancia a tormenta de reintentos bajo lentitud simulada del endpoint.
- Detección de fallos silenciosos verificando el estado de negocio resultante, no solo la respuesta 200.
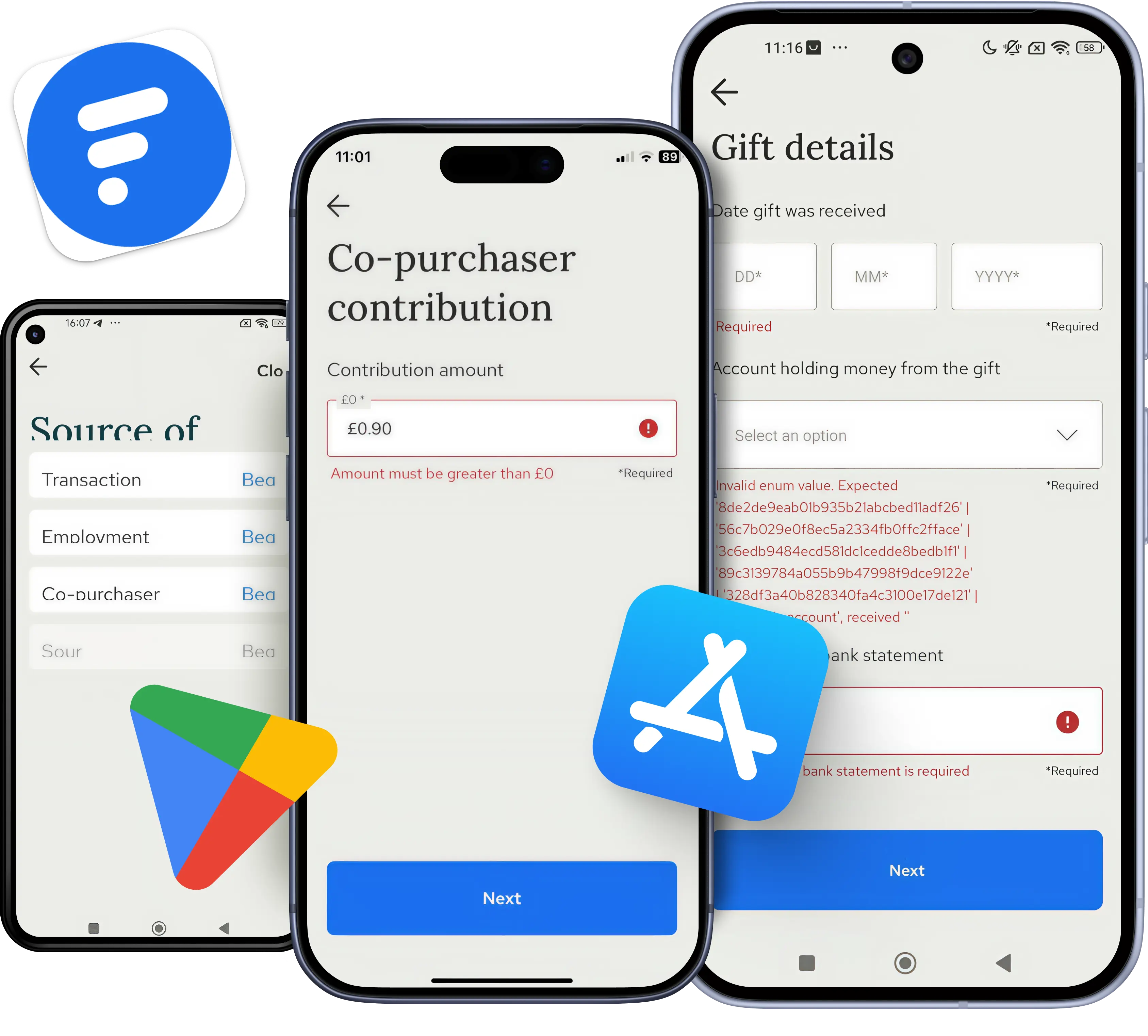
Expiración de tokens a mitad de sesión
Los tokens OAuth expiran. Existe lógica de refresco. Ambas cosas son obvias. Lo que es menos obvio es qué ocurre cuando el token de acceso expira durante un flujo de usuario de larga duración, cuando dos trabajos en segundo plano intentan refrescar el mismo token de forma concurrente, o cuando el proveedor rota silenciosamente los tokens de refresco y la aplicación sigue usando el antiguo. Google revoca los tokens de refresco después de siete días para las apps en modo de prueba, después de seis meses de inactividad, e inmediatamente cuando un usuario cambia su contraseña si hay ámbitos de Gmail involucrados. Nada de esto aparece en una pasada de QA de 30 minutos.
La solución es forzar la expiración del token como condición de prueba. Simular un 401 a mitad de sesión, ejecutar refrescos concurrentes contra la misma conexión, y verificar que la aplicación tiene éxito con el nuevo token o muestra un prompt de re-autenticación limpio. Las pruebas de desviación de reloj detectan la clase silenciosa de fallos donde el servidor cree que el token es válido y el proveedor discrepa en 30 segundos.
Respuestas de éxito que ocultan fallos
Este es el modo de fallo que atrapa con más frecuencia a las suites de pruebas ingenuas. La API de Slack, varias pasarelas de pago y la mayoría de las plataformas de mensajería devuelven HTTP 200 con el fallo codificado en el cuerpo JSON: "ok":false, "status":"failed", o un array errors. Una prueba que verifica el código de estado pasa. El flujo orientado al usuario falla aguas abajo porque la aplicación trató la respuesta como éxito.
El remedio es verificar la semántica del payload en lugar del estado del transporte. Las pruebas funcionales de API en este límite implican validación de esquema en cada respuesta, aserciones de estado de negocio que verifican que la acción realmente ocurrió, y una capa de normalización que convierte las formas de error específicas del proveedor en un contrato de error interno consistente. Aquí es también donde las pruebas de contrato de API se ganan su lugar: los contratos detectan el momento en que cambia la forma de respuesta de un proveedor, antes de que ese cambio llegue a los usuarios. Un proceso de pruebas de integración maduro integra estos contratos en el pipeline de lanzamiento en lugar de tratarlos como un ejercicio puntual.
Colisiones de límite de tasa y cuota
En la suite de pruebas aislada de una funcionalidad, la integración usa el 5% del presupuesto de límite de tasa del proveedor. En producción, el manejador de webhooks, el trabajo de sincronización en segundo plano, la función de exportación y el nuevo panel comparten el mismo pool. La integración que pasó todas las pruebas empieza a devolver 429s bajo carga combinada.
Las colisiones de límite de tasa se sitúan en la costura entre las pruebas funcionales y de rendimiento. Las mismas auditorías donde aparecen estas colisiones también sacan a la luz otros cuellos de botella de API que pasan todas las pruebas aisladas pero fallan bajo carga de producción combinada. Como mínimo, el QA funcional debería:
- Ejecutar pruebas de funcionalidades concurrentes contra el mismo sandbox del proveedor para exponer la contención del pool.
- Verificar el manejo correcto del 429: respetar
Retry-After, aplicar jitter, evitar estampidas en la recuperación. - Verificar que la decisión fail-open frente a fail-closed de la aplicación es intencional y no accidental.
Deriva de esquema y contrato
Los proveedores cambian sus APIs. Añaden campos, deprecan otros, refuerzan la validación o silenciosamente cambian un string a un enum. Las pruebas que se ejecutan contra mocks construidos hace seis meses seguirán pasando mientras la producción falla en la primera llamada real después del despliegue del proveedor. Este es el patrón detrás de los fallos de integración silenciosos que tardan días en diagnosticarse porque nada en el código cambió.
La defensa son las pruebas de contrato programadas contra el sandbox del proveedor en vivo, más allá del CI. Una verificación de contrato diaria que llame al endpoint real y valide la forma de la respuesta contra un esquema almacenado es suficiente para detectar la mayoría de la deriva antes que los usuarios. Combínala con validación estricta de esquema en cada respuesta de producción para que un tipo de campo inesperado falle con ruido en lugar de corromper el estado silenciosamente.
Cómo probar funcionalmente las integraciones de terceros
El reflejo cuando las integraciones fallan es escribir más pruebas. El movimiento mejor es escribir pruebas diferentes, organizadas en torno a cómo fallan realmente las integraciones. Tres principios separan a los equipos que detectan estos problemas de los que lanzan y esperan.
Prueba los modos de fallo junto al camino feliz. Fuerza timeouts. Inyecta respuestas 5xx. Devuelve payloads malformados. Expira tokens a mitad del flujo. La mayoría de los errores de integración viven en los caminos de error que la suite de pruebas nunca ejercita, porque la suite fue construida para confirmar que la funcionalidad funciona en lugar de confirmar que la funcionalidad degrada de forma segura.
Combina mocks con verificaciones de contrato en vivo. Los mocks son rápidos, deterministas y necesarios para la cobertura a nivel unitario. También son la razón por la que la deriva de esquema pasa desapercibida. Una tabla corta hace concreto el equilibrio:
Enfoque
Detecta
No detecta
Mejor para
Enfoque
Respuestas mock
Detecta
Lógica de la aplicación contra una forma conocida
No detecta
Cambios del lado del proveedor, latencia real, errores reales
Mejor para
Ejecuciones unitarias y de CI
Enfoque
Pruebas en sandbox
Detecta
Flujos de autenticación, forma del payload, comportamiento de reintento
No detecta
Carga de producción, contención del pool, latencia del mundo real
Mejor para
Validación previa al lanzamiento
Enfoque
Verificaciones de contrato en vivo
Detecta
Deriva de esquema, campos deprecados, cambios de comportamiento
No detecta
Lógica de la aplicación
Mejor para
Monitoreo programado contra el proveedor real
Trata la telemetría de producción como parte del QA. Las pruebas funcionales para aplicaciones web integradas continúan después del lanzamiento. Realiza seguimiento de señales específicas de integración: tasa de picos de 401, porcentaje de éxito de entrega de webhooks, frecuencia de tormentas de reintento, latencia p95 por proveedor. Estas son las métricas que confirman lo que el staging prometió. Las pruebas de integración para aplicaciones web solo merecen su nombre cuando incluyen este bucle de retroalimentación, y es exactamente el bucle que las sólidas pruebas de integración de API incorporan por defecto.
Una lista de verificación de casos de prueba para aplicaciones web integradas
Una lista de verificación inicial para el QA de la capa de integración, organizada por tipo de integración. Cada elemento en ella es algo que ha fallado en producción al menos una vez en auditorías recientes.
Integraciones de pago
- Tarjeta rechazada en el lado del proveedor: ¿el pedido hace rollback correctamente?
- 200 OK con
status:faileden el cuerpo: ¿la aplicación expone el fallo? - ¿Firma del webhook inválida: rechazada y registrada?
- ¿Entrega duplicada de webhook: clave de idempotencia respetada?
OAuth y proveedores de identidad
- ¿Token de acceso expirado a mitad de la solicitud: el refresco ocurre de forma transparente?
- ¿Dos refrescos concurrentes: solo uno se activa, ambos tienen éxito?
- ¿Token de refresco rotado por el proveedor: nuevo token almacenado?
- ¿El usuario revoca el acceso: la aplicación lo detecta y solicita re-autenticación?
Webhooks en general
- ¿Entrega fuera de orden manejada?
- ¿Reintento dentro de una ventana válida: deduplicado?
- ¿Endpoint lento: política de reintento del proveedor respetada sin pérdida de datos?
APIs de terceros
- Validación de esquema en cada respuesta, más allá del código de estado.
- 429 con
Retry-After: ¿respetado con jitter? - ¿El proveedor devuelve campo deprecado: registrado para acción?
- ¿Partición de red: el circuit breaker se abre correctamente?
Esta es la cobertura que las sólidas pruebas de aplicaciones web incorporan en los pipelines de lanzamiento desde la capa de integración hacia arriba.
El costo en QA funcional de fallar en las integraciones
El costo de un fallo de integración en producción rara vez aparece como una sola línea en un informe. Aparece como un canal de incidentes el lunes por la mañana, un CFO preguntando por qué cayeron los pagos durante el fin de semana, capturas de pantalla de clientes circulando en redes sociales, y un sprint de ingeniería perdido en el análisis post-mortem. El patrón es consistente en todas las auditorías: el error que aparece en producción no estaba en el código que cambió, estaba en la costura entre el código interno y un proveedor cuyo comportamiento nadie controla.
Detectar estos fallos antes se reduce a probar esas costuras con el mismo rigor que las funcionalidades que las rodean. Contáctanos y revisaremos juntos dónde probablemente se ocultan las brechas.
FAQ
¿Por qué los errores de integración de terceros se escapan del QA?
El staging y la producción son entornos estructuralmente diferentes. Las APIs de sandbox responden más rápido, los tokens no expiran a mitad del flujo, los mocks siempre coinciden con el esquema esperado y los límites de tasa nunca colisionan porque ninguna otra funcionalidad compite por el mismo pool. Un plan de pruebas construido en torno al staging supera todo lo que el staging puede fallar, y pasa por alto todo lo que solo la producción puede romper.
¿Cuál es la diferencia entre las pruebas funcionales y las pruebas de integración para aplicaciones web?
Las pruebas funcionales verifican que una funcionalidad hace lo que su especificación dice que debe hacer. Las pruebas de integración verifican que dos o más componentes funcionan correctamente cuando están conectados. Un QA sólido para sistemas integrados usa ambas, con aserciones funcionales escritas en el límite de integración en lugar de solo en la interfaz.
¿Cuál es la diferencia entre sandbox y producción para las integraciones de terceros?
Los sandboxes son clones simplificados construidos para el desarrollo. Omiten la carga de nivel de producción, la latencia del mundo real, el comportamiento real de los límites de tasa y la superficie de errores completa del proveedor. Plaid, Stripe y la mayoría de los transportistas documentan públicamente esta brecha, con la latencia de webhooks en sandbox típicamente en 100 a 200 ms mientras que la producción promedia 2 a 5 segundos.
Mira cómo entregamos flujos estables de incorporación, verificaciones de identidad y flujos de Origen de Fondos para una fintech del Reino Unido construida sobre integraciones profundas de terceros.