¿Tu API no funciona como esperabas? ¿Se acumulan los problemas y no tienes ni idea de por qué, ya que superó todas las pruebas que tu equipo le realizó? Si esto te suena familiar, este podría ser el caso de cómo las pruebas de rendimiento de API son fundamentalmente diferentes de las pruebas previas al lanzamiento, y por qué esa diferencia se traduce directamente en tus ingresos.
Llevamos años realizando auditorías de API en plataformas fintech, productos SaaS y aplicaciones para consumidores, y los mismos problemas aparecen en casi todos los proyectos. No por negligencia de los equipos, sino porque estos problemas son invisibles hasta que se hacen evidentes. Hoy, compartiremos exactamente lo que nuestros expertos suelen observar durante las pruebas de rendimiento de las API.
Lo que las pruebas de rendimiento de API realmente revelan (y que las pruebas unitarias no)
La historia suele ser así: tu API funciona perfectamente antes de su lanzamiento. Los endpoints devuelven los datos correctos, los códigos de error se comportan como se espera y la lista de verificación de control de calidad está impecable. Luego, se lanza, el tráfico aumenta y algo falla silenciosamente. Por lo general, esto incluye tiempos de respuesta cada vez mayores, integraciones de terceros que caducan y usuarios en tu aplicación móvil viendo un indicador de carga que nunca se detiene. Para cuando tu equipo aísla el problema, el daño ya está hecho. Ahora tienes clientes insatisfechos, un SLA incumplido o un pago fallido que alguien captura y publica en línea.
Esta es la brecha que las pruebas de rendimiento de API especializadas buscan cerrar. No se trata de simples casillas de verificación, sino de pruebas que simulan lo que tu API enfrenta en el mundo real: cientos de usuarios concurrentes, picos de tráfico impredecibles y servicios de proveedores que fallan en el peor momento posible. Según la investigación de Cloudflare sobre rendimiento web y conversiones, un retraso de dos segundos en el tiempo de respuesta conlleva una pérdida aproximada del 4 % en los ingresos por visitante. Para una empresa que factura 5 millones de dólares al año en línea, esto representa un problema de 200 000 dólares oculto tras lo que parece ser un producto que funciona a la perfección.
Las pruebas unitarias confirman que una función individual realiza su función de forma aislada. Son útiles, pero no revelan prácticamente nada sobre el comportamiento de la API cuando 300 usuarios la acceden simultáneamente, cuando la base de datos ya está sobrecargada por un proceso en segundo plano o cuando una dependencia de terceros decide responder en 8 segundos en lugar de 80 milisegundos.
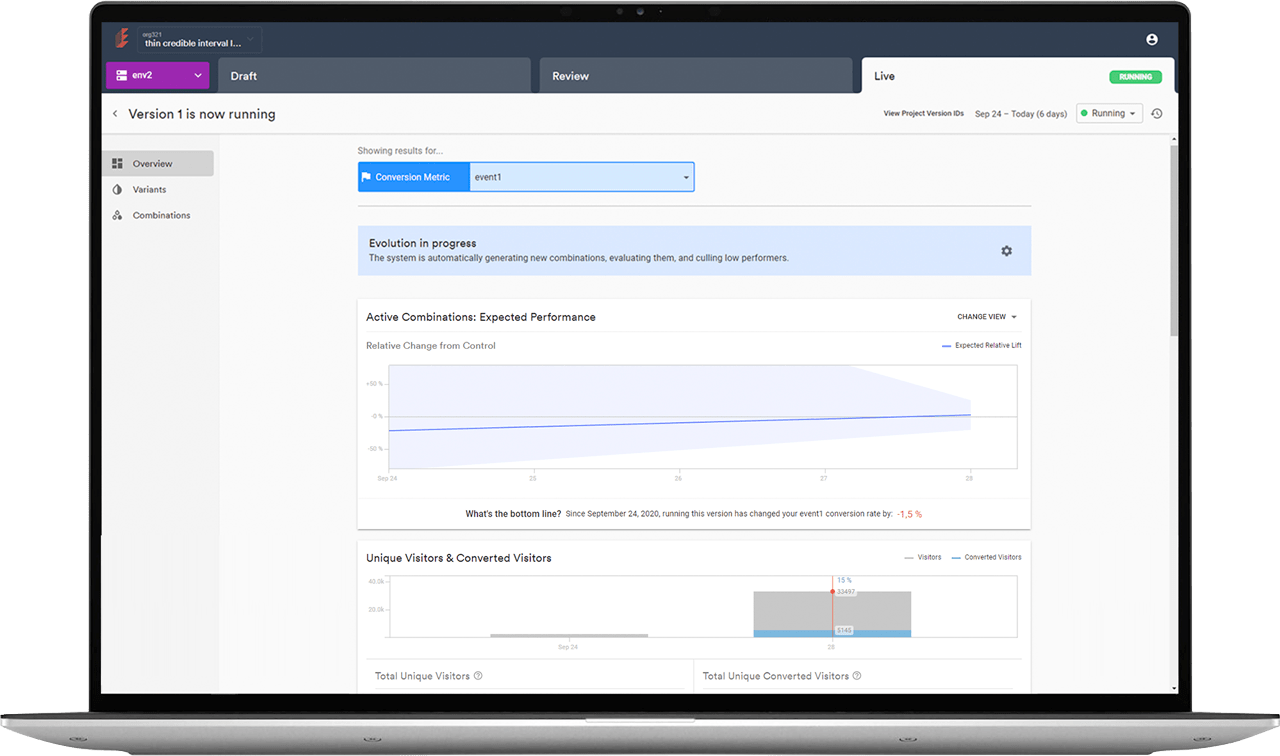
Las pruebas de rendimiento para API recrean las condiciones clave: un número realista de usuarios concurrentes, volúmenes de datos representativos de un entorno de producción y los picos de tráfico que se producen el día del lanzamiento o durante una campaña promocional. Es el único método que revela el estado de su sistema justo cuando su empresa más lo necesita. Si le parece importante saber esto antes de que sus usuarios lo descubran, siga leyendo.

7 cuellos de botella que observamos en todas las auditorías de pruebas de rendimiento de API
Los cuellos de botella que se describen a continuación no son casos hipotéticos sacados de un libro de texto. Son hallazgos que aparecen repetidamente en nuestros informes de auditoría en diversos sectores, tecnologías y tamaños de equipo. Algunos les resultarán familiares, pero si más de dos de ellos se parecen a algo que podría existir en su producto ahora mismo, es una señal de que debería empezar a abordarlos antes de que se conviertan en una captura de pantalla de otra persona.
Cuello de botella 1: Patrones de consulta de base de datos no optimizados bajo carga
Cada punto final de la API suele funcionar perfectamente al probarlo individualmente. Se envía una solicitud, se obtiene una respuesta en 50 milisegundos y listo. El problema surge cuando 200 usuarios realizan la misma acción simultáneamente y la base de datos ejecuta una consulta independiente para cada elemento de la lista en lugar de obtener todos los datos a la vez.
Esto se conoce como el problema de las consultas N+1, y es uno de los hallazgos más comunes en las auditorías de rendimiento de las API web. Un endpoint que devuelve una lista de 50 pedidos podría generar 51 consultas a la base de datos por solicitud: 50 búsquedas individuales más una para la lista en sí. Si multiplicamos esto por el número de usuarios concurrentes, obtenemos una API rápida que se vuelve lenta sin que haya una sola línea de código deficiente que sea evidente de forma aislada.
La falta de índices en la base de datos agrava aún más el problema. Sin ellos, cada consulta escanea tablas completas en lugar de acceder directamente a las filas relevantes. Bajo carga, esto se traduce directamente en picos de latencia y tiempos de espera agotados que las pruebas funcionales nunca detectarán, ya que estas no ejecutan la consulta bajo una presión concurrente significativa.
La solución no es complicada una vez que se sabe que existe el problema. Simplemente requiere realizar pruebas de carga de la API en condiciones realistas para detectarlo.
Cuello de botella 2: Agotamiento del grupo de conexiones
Tu API se conecta a una base de datos mediante un conjunto de conexiones preestablecidas, en lugar de abrir una nueva para cada solicitud. Este conjunto tiene un límite de tamaño, y cuando todas las conexiones disponibles están en uso, las nuevas solicitudes esperan. En las pruebas de carga de la API con usuarios concurrentes reales, este límite se alcanza con sorprendente rapidez.
La mayoría de los equipos configuran los grupos de conexiones en función de la carga promedio prevista. El problema es que la carga promedio no es lo que colapsa los sistemas, sino los picos de tráfico. Se envía un correo electrónico promocional, un producto se destaca en algún sitio, un procesador de pagos se ralentiza y mantiene las conexiones abiertas más tiempo de lo habitual, y de repente el grupo de conexiones se agota. Se acumulan nuevas solicitudes en la cola, los tiempos de espera superan los límites y los usuarios ven errores.
Aquí es donde se hace evidente la relación entre rendimiento y arquitectura. Un grupo de servidores diseñado para un promedio de 100 usuarios concurrentes fallará con menos de 300, incluso si sus servidores cuentan con suficiente capacidad de CPU y memoria. Conocer el límite real antes de que los usuarios lo descubran es precisamente lo que buscan las pruebas de estrés previas al lanzamiento.
Cuello de botella 3: Tiempos de espera agotados en dependencias de terceros sin mecanismo de reserva
Las API modernas rara vez funcionan de forma aislada. Pasarelas de pago, servicios de detección de fraude, API de geolocalización, plataformas de envío de correo electrónico: es probable que tu producto utilice varias de ellas con cada acción relevante del usuario. Cuando uno de estos servicios externos se ralentiza o se desconecta, ¿qué hace tu API?
Si la respuesta es “esperar indefinidamente” o “devolver un error 500”, existe este cuello de botella. Y según el informe “Estado de la fiabilidad de las API 2025” de Uptrends, el tiempo de actividad promedio de las API en todos los sectores cayó al 99,46 % en el primer trimestre de 2025, frente al 99,66 % del año anterior, lo que significa que el riesgo de ralentizaciones por parte de terceros está aumentando, no disminuyendo.
Una API sin configuración de tiempo de espera para las llamadas salientes ni lógica de disyuntor para degradar el rendimiento de forma controlada cuando un proveedor tiene problemas, superará todas las pruebas funcionales. Solo se manifestará como un problema cuando el proceso de pago se bloquee debido a que una API de geolocalización en otra región responde con lentitud. Las pruebas de rendimiento de la API con latencia inyectada en las llamadas a terceros son la única forma fiable de comprobar cómo se comporta realmente el sistema cuando los proveedores de los que depende no cooperan.
Cuello de botella 4: Tamaños de carga útil ineficientes (sobrecarga y subcarga)
Tu API devuelve 40 campos por objeto, pero tu aplicación móvil solo muestra seis. Los otros 34 se obtienen, se serializan, se transmiten a través de la red y luego el cliente los ignora silenciosamente. Ahora multiplica eso por cada llamada a la API que realiza tu aplicación por sesión y por cada usuario concurrente.
La sobrecarga de datos es un problema muy común en las auditorías de rendimiento de las API web, especialmente en bases de código REST antiguas donde los puntos finales se diseñaron para un caso de uso y luego se reutilizaron en muchos otros. El costo en ancho de banda es real, la sobrecarga de serialización añade latencia y, en redes móviles donde cada byte cuenta, el impacto en la experiencia del usuario es tangible.
La carga incompleta es el problema inverso. Un cliente necesita datos de cinco objetos para mostrar una sola pantalla, por lo que realiza cinco llamadas a la API de forma secuencial, lo que implica cinco viajes de ida y vuelta en lugar de uno. En un entorno móvil con una conexión inestable, esto se traduce en tiempos de carga visibles incluso cuando cada llamada individual es rápida.
Cuando trabajábamos con Union54, la primera API de emisión de tarjetas de África, uno de los errores que detectó nuestro equipo consistía en que un endpoint devolvía datos obsoletos o incorrectos en su respuesta, a pesar de que la base de datos contenía los valores correctos. El saldo y el estado de la tarjeta en la respuesta de la API no coincidían con los almacenados en la base de datos tras el cambio de estado de la tarjeta. En el contexto de las fintech, este tipo de discrepancia entre los datos que envía la API y los que el sistema realmente almacena es precisamente el tipo de problema que las pruebas de rendimiento e integración bajo cargas reales están diseñadas para detectar. Union54 logró recaudar 15 millones de dólares en financiación inicial, y el producto se resolvió de los problemas críticos antes de su día de demostración para inversores.
Cuello de botella 5: Sobrecarga de autenticación y validación de tokens en cada solicitud
Tu API está protegida con tokens, lo cual es correcto. La cuestión es qué sucede con cada solicitud autenticada. Si tu API llama a un servicio de identidad externo o accede a la base de datos para verificar una sesión en cada solicitud sin ningún tipo de almacenamiento en caché, introduces una latencia que se agrava con el aumento de la escala.
La sobrecarga de autenticación suele pasar desapercibida durante el desarrollo, ya que la validación es rápida cuando el servicio de identidad está en funcionamiento y la tabla de usuarios es pequeña. Sin embargo, las pruebas de carga de API realistas suelen demostrar que, con una caché vacía y una tabla de usuarios con millones de filas, la misma validación que tardaba 5 milisegundos en el entorno de pruebas tarda 120 milisegundos en producción. Si multiplicamos esto por cada llamada a la API en cada sesión de usuario, el impacto en el rendimiento percibido es significativo.
Almacenar en caché los resultados de la validación de tokens durante un breve período adecuado elimina la mayor parte de esta sobrecarga. Sin embargo, la solución requiere conocer la existencia del problema, lo que implica realizar pruebas de rendimiento de las API bajo una carga concurrente real, en lugar de en un entorno de prueba con un solo usuario.
Cuello de botella 6: Limitación de velocidad y restricción de ancho de banda faltantes o mal configuradas
Una API sin limitación de velocidad es una invitación abierta a que las cosas salgan mal, no solo por parte de agentes maliciosos, sino también por fallos en tus propios sistemas. Cuando un servicio experimenta un error y vuelve a intentar la misma solicitud en un bucle, o cuando una integración de cliente falla y envía miles de solicitudes en segundos, una API desprotegida absorbe todo el impacto.
El ranking OWASP API Security Top 10 sitúa el consumo ilimitado de recursos en el cuarto puesto de la lista de riesgos críticos de seguridad de las API, precisamente porque la falta de controles de limitación de velocidad y restricción de tráfico supone tanto un problema de rendimiento como una vulnerabilidad de seguridad. Una API que puede verse saturada por una avalancha de reintentos accidentales derivada de una integración legítima es igualmente vulnerable a un intento deliberado de denegación de servicio.
La limitación de velocidad no se limita a establecer un umbral de solicitudes por minuto a nivel de puerta de enlace. También implica limitar la velocidad a nivel de usuario, IP y punto final, establecer tiempos de espera adecuados y garantizar que la API gestione los fallos de forma controlada en lugar de provocar una cascada de fallos. Nuestras pruebas de seguridad y rendimiento suelen revelar esta brecha de forma conjunta, razón por la cual ambas disciplinas están más relacionadas de lo que la mayoría de los equipos suponen. Si desea profundizar en cómo se explotan en la práctica las vulnerabilidades a nivel de API, nuestra lista de verificación de pruebas de penetración web cubre en detalle la relación entre las debilidades de rendimiento y la exposición a la seguridad.
Cuello de botella 7: No hay parámetros de referencia de rendimiento ni umbrales de SLA definidos
Este es el más invisible de todos, porque no hay nada que esté fallando. Tu API funciona, los tiempos de respuesta parecen razonables y nadie se ha quejado todavía.
Sin embargo, “razonable” y “aceptable” no son lo mismo a menos que se haya definido qué significa realmente aceptable. Sin parámetros de referencia de rendimiento documentados ni umbrales de SLA (Acuerdo de Nivel de Servicio), su equipo no tiene forma de saber si la implementación de la semana pasada ralentizó su API un 30 %. No hay un punto de referencia con el que comparar, ni una alerta que se active cuando la latencia P95 supere un umbral significativo, ni una definición de lo que constituye un buen rendimiento que pueda incorporarse a una comprobación del pipeline de CI/CD.
Así es como las regresiones de rendimiento se acumulan silenciosamente durante meses de desarrollo. Cada lanzamiento añade una pequeña latencia, mientras que ninguna implementación individual parece alarmante. Seis meses después, una API que antes respondía en 80 milisegundos ahora tarda 400. Según el informe State of the API de Postman, entre 26 y 50 API impulsan actualmente la aplicación empresarial promedio. En ese entorno, una regresión de rendimiento en una API se propaga a través de los servicios dependientes de tal manera que resulta extremadamente difícil rastrear la causa raíz a posteriori. El artículo sobre las fases de las pruebas de software en nuestro blog explica precisamente por qué detectar estos problemas al principio del ciclo de desarrollo cuesta una fracción de lo que cuesta investigarlos en producción.
Por qué estos cuellos de botella permanecen ocultos hasta que es demasiado tarde
Todos los problemas mencionados comparten una característica común: son indetectables mediante pruebas que no replican las condiciones de producción. Un entorno de prueba con un solo usuario, una base de datos pequeña y limpia, cachés activas y sin latencia de terceros inyectada, permitirá que una API que falla estrepitosamente bajo carga real funcione correctamente. Estos cuellos de botella se encuentran en la brecha entre los entornos de preproducción y producción, esperando silenciosamente el momento en que el negocio dependa realmente del rendimiento de la API.
El momento de encontrarlos es antes de que llegue ese momento.
Si dos o tres de los cuellos de botella mencionados te resultan familiares, no te preocupes. Es un patrón común en equipos de todos los tamaños y niveles de experiencia, ya que estos problemas solo se manifiestan en condiciones que la mayoría de los equipos no suelen generar. La buena noticia es que detectarlos es sencillo una vez que se realizan las pruebas correctamente, con una carga realista, datos representativos del entorno de producción y la ayuda de alguien que sepa qué buscar.
Para eso están diseñadas nuestras auditorías de rendimiento de API. Las hemos realizado para API de fintech que gestionan transacciones con dinero real, para plataformas SaaS que dan servicio a clientes empresariales con estrictos acuerdos de nivel de servicio (SLA) de disponibilidad, y para aplicaciones de consumo donde el tiempo de respuesta marca la diferencia entre un usuario que se queda y uno que desinstala la aplicación. Cuando esté listo para ver cómo se comporta su API bajo presión, llámenos.
Descubre cómo nuestras pruebas ayudaron a una herramienta de IA para el crecimiento digital a aumentar la velocidad de las pruebas de regresión en un 50 %.