
El sector de los agentes de IA está evolucionando rápidamente, pero el impacto real de estos agentes (y hasta qué punto podemos confiar en ellos) depende de una evaluación exhaustiva. Comencemos por explorar la definición de agente de IA: sistemas de software que utilizan inteligencia artificial para realizar tareas de forma autónoma e interactuar con otros agentes con el fin de alcanzar objetivos complejos y compuestos.
La evaluación de agentes de IA implica valorar la eficacia, la fiabilidad, la seguridad y el rendimiento de un agente de IA en situaciones reales. A diferencia del software convencional, los agentes de IA presentan retos únicos. Entre ellos se incluyen comportamientos nuevos e inesperados, resultados que no podemos predecir y problemas de seguridad. Por lo tanto, la evaluación de los agentes es crucial para reducir los riesgos. Nuestra guía ofrece una visión general concisa de las métricas clave para la evaluación de agentes de IA y métodos prácticos para evaluar con precisión el rendimiento de los agentes.
Por qué es importante la evaluación de los agentes de IA
Los agentes de IA no probados o mal evaluados pueden causar problemas importantes a cualquier empresa. Piensa en las pérdidas económicas derivadas de respuestas erróneas, el daño a la reputación por acciones injustas o incluso las fugas de datos en los sistemas automatizados.
A medida que las empresas pasan de simples implementaciones basadas en el chat a marcos más avanzados que hacen hincapié en la colaboración entre múltiples agentes y en capacidades más autónomas, la necesidad de métodos fiables de evaluación de los agentes de IA no hace más que aumentar. Las empresas deben reconocer los aspectos cruciales que merecen su consideración:
- Garantía de rendimiento: garantiza que los agentes realicen sus tareas de manera eficiente y correcta. Según la encuesta de LangChain, el 41 % de los líderes tecnológicos consideran que la calidad del rendimiento es una de sus principales preocupaciones.
- Seguridad y fiabilidad: detecta comportamientos dañinos o no deseados. La privacidad de los datos supone un reto, y el 53 % de los encuestados en otro estudio expresaron su preocupación al respecto.
- Confianza del usuario: establece la confianza a través de la transparencia y la explicabilidad.
- Alineación ética: verifica el cumplimiento de las directrices éticas y la privacidad.
- Cumplimiento normativo: garantiza que los agentes cumplan los requisitos legales y normativos pertinentes.
- Mejora continua: identifica áreas de mejora iterativa.
Al evaluar periódicamente los agentes de IA y comprobar su rendimiento, se obtiene una prueba clara de que las soluciones de IA son fiables, eficaces y están listas para su uso en el mundo real.
Métricas clave para la evaluación de agentes de IA
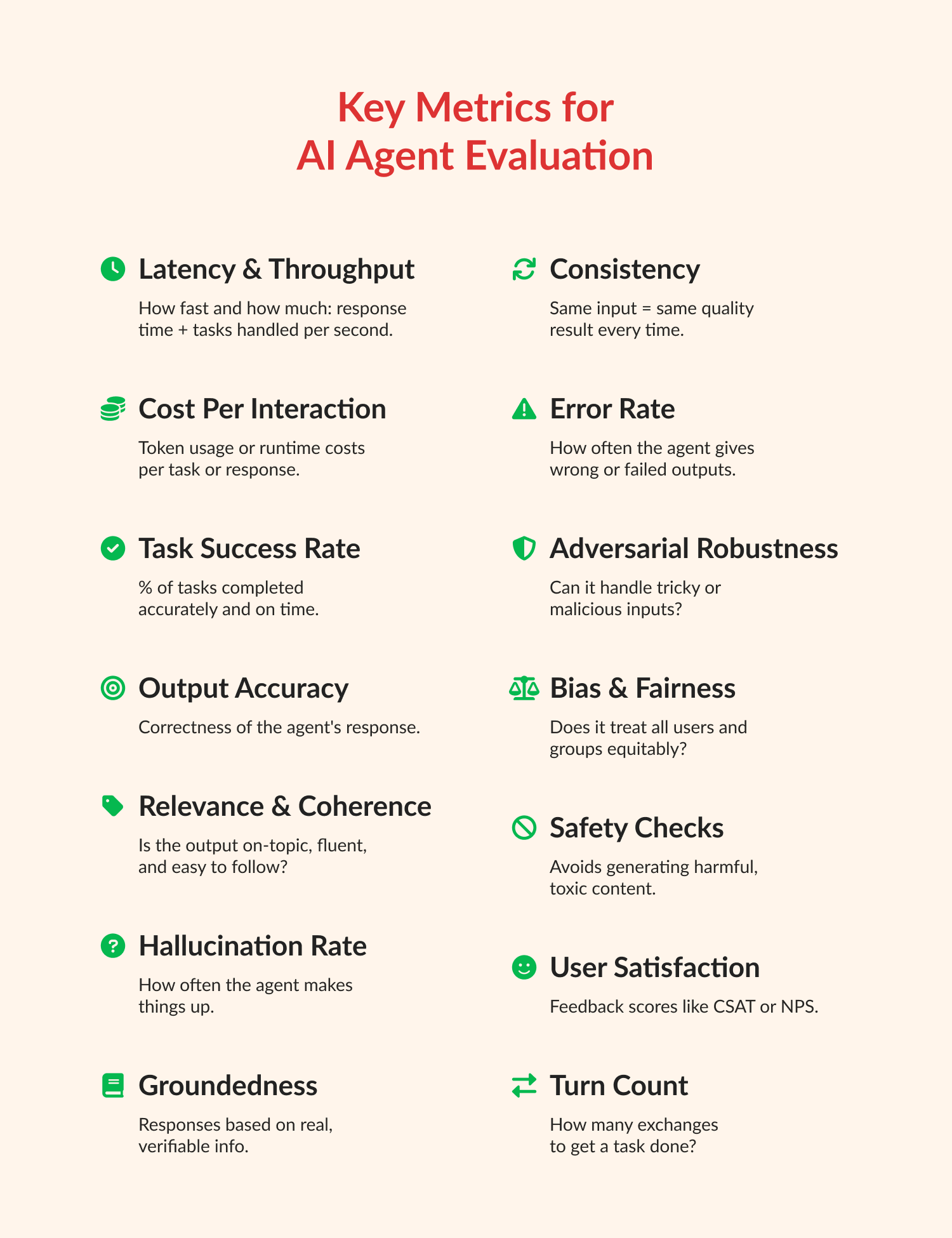
La medición del rendimiento de los agentes implica tener en cuenta muchos aspectos diferentes. No hay una única puntuación que lo diga todo. En su lugar, utilizamos varias métricas importantes de evaluación de agentes de IA para obtener una visión completa del rendimiento de un agente de IA.
Métricas de rendimiento y eficiencia
Estas métricas se centran en la rapidez y eficiencia con la que un agente de IA completa sus tareas, así como en los recursos que utiliza.
- Latencia/tiempo de respuesta: se refiere a la velocidad a la que el agente responde a una solicitud o completa una tarea. Un tiempo menor significa un agente más receptivo, lo cual es vital para una buena experiencia de usuario.
- Rendimiento: mide el número de tareas o solicitudes que un agente puede gestionar en un plazo de tiempo determinado. Un rendimiento mayor significa que el agente puede gestionar más trabajo.
- Coste por interacción/uso de tokens: examina el coste operativo asociado a cada tarea o interacción. En el caso de los agentes basados en LLM, esto suele incluir el número de «tokens» (partes de palabras) procesados, ya que esto afecta a la facturación y al consumo de recursos.
- Tasa de éxito/finalización de tareas: se refiere al porcentaje de tareas que el agente completa dentro del plazo previsto. Muestra directamente si el agente está alcanzando sus objetivos.
Métricas de calidad y precisión de los resultados
Estas métricas evalúan la calidad, la precisión y la claridad del contenido o las acciones generadas por el agente.
- Precisión: mide en qué medida los resultados del agente se ajustan a la respuesta correcta o al resultado deseado. Se trata de hacer las cosas bien.
- Relevancia: comprueba si la respuesta del agente está realmente relacionada y es útil para la pregunta o tarea del usuario.
- Coherencia y fluidez: en el caso de los agentes que generan texto, evalúa lo naturales, lógicas y gramaticalmente correctas que suenan sus respuestas.
- Tasa de alucinaciones: es una métrica crucial para los LLM. Mide la frecuencia con la que el agente crea información que es objetivamente incorrecta o inventada. Puede encontrar más información sobre cómo combatir las alucinaciones de la IA en la Capitol Technology University.
- Fundamentación: comprueba si las respuestas del agente se basan en información real y verificable, principalmente cuando se basan en fuentes de conocimiento específicas (algo habitual en los sistemas RAG).
Métricas de robustez y fiabilidad
Estas métricas nos ayudan a comprender la estabilidad y consistencia de un agente de IA, incluso cuando se enfrenta a situaciones difíciles o inesperadas.
- Consistencia: significa que el agente proporciona respuestas similares y correctas cuando se le plantean preguntas iguales o muy similares varias veces.
- Tasa de error: esta métrica indica la frecuencia con la que el agente comete errores o no responde correctamente. Cuanto menor sea la tasa de error, mejor.
- Resistencia a los ataques adversarios: esta medida comprueba la capacidad del agente para gestionar entradas diseñadas para engañarlo o hacer que falle intencionadamente. Se trata de seguridad y estabilidad.
Métricas de seguridad y ética
Estas métricas son fundamentales para garantizar que los agentes de IA se utilicen de forma responsable y no causen daños.
- Detección de sesgos: identifica si los resultados del agente muestran un trato injusto hacia diferentes grupos de personas (por motivos de género, raza o edad).
- Generación de contenido perjudicial: mide la frecuencia con la que el agente genera contenido tóxico, ofensivo o inapropiado.
- Métricas de equidad: son métodos medibles para evaluar si el agente trata a todo el mundo de forma equitativa y ética.
Métricas de experiencia del usuario
Aunque a veces es más difícil de medir, la experiencia del usuario es crucial para la percepción que las personas tienen del agente de IA y su interacción con él.
- Puntuaciones de satisfacción del usuario (por ejemplo, CSAT, NPS): Estas puntuaciones se obtienen a partir de los comentarios directos de los usuarios sobre su satisfacción con el rendimiento del agente.
- Número de turnos: Esta métrica mide el número de mensajes o turnos que necesita el agente para completar la solicitud de un usuario. Un menor número de turnos suele significar una experiencia más fluida.
Lista de verificación para la evaluación de agentes de IA
Cómo evaluar los agentes de IA: métodos y marcos
Para evaluar eficazmente los agentes de IA, es necesario adoptar un enfoque claro y estructurado. Este enfoque no consiste solo en realizar pruebas, sino en crear un marco sólido de evaluación de agentes de IA que le ayude a comprender y mejorar las capacidades de su IA. Para ello, es necesario pasar por las fases clave de las pruebas de software.
Definición de objetivos y criterios
En primer lugar, defina claramente lo que quiere que logre su agente de IA. ¿Cuáles son sus tareas principales? ¿Cómo sabrá si tiene éxito? Establecer criterios claros de evaluación de los agentes de IA desde el principio ayuda a orientar todo el proceso de evaluación. Estas definiciones iniciales son cruciales porque dictan qué métricas de evaluación de los agentes de IA son más relevantes y cómo se medirá el éxito, lo que garantiza que sus esfuerzos sean específicos y significativos.
Por ejemplo, si su agente de IA es un bot de atención al cliente, un objetivo fundamental podría ser «resolver el 85 % de las consultas habituales de los usuarios sin intervención humana». Este objetivo destaca inmediatamente métricas clave como la «tasa de éxito» y la «eficiencia conversacional». Sin objetivos tan precisos, la evaluación del agente se convierte en un ejercicio vago, lo que dificulta identificar las áreas de mejora o afirmar con confianza su valor para la empresa.
Selección de datos y casos de prueba diversos
A continuación, recopile una amplia gama de datos de prueba. Deben incluir escenarios comunes en el mundo real, así como «casos extremos» complicados o entradas diseñadas para poner a prueba al agente (ejemplos adversos). La creación de indicaciones o interacciones específicas adaptadas a estas diversas condiciones ayuda a poner a prueba las capacidades del agente más allá del uso típico, revelando lo robusto y fiable que es realmente en circunstancias variadas.
Una diversidad de datos insuficiente puede dar lugar a fallos evidentes en la implementación. Por ejemplo, un agente de IA entrenado únicamente con texto formal y perfectamente redactado puede tener dificultades para comprender las consultas reales de los usuarios que incluyen jerga, errores ortográficos o lenguaje ambiguo. Del mismo modo, supongamos que un agente de IA visual se entrena únicamente con imágenes tomadas en condiciones de iluminación perfectas. En ese caso, puede fallar en condiciones de poca luz, lo que daría lugar a comportamientos inesperados y a un rendimiento deficiente del agente en el mundo real.
Elección de estrategias de evaluación
Hay diferentes formas de realizar las evaluaciones y, a menudo, lo mejor es combinar varias:
- Pruebas y evaluaciones automatizadas: este enfoque es rápido y coherente. Se somete al agente a numerosas tareas y los ordenadores registran automáticamente las métricas. Esto es ideal para comprobar aspectos como la precisión o la rapidez de respuesta (por ejemplo, utilizando comprobaciones basadas en reglas u otros modelos para puntuar los resultados).
- Evaluaciones con intervención humana: para aspectos que los ordenadores no pueden juzgar fácilmente, como el tono, la creatividad o la naturalidad de una conversación, se necesitan revisores humanos. Los métodos incluyen pedir a las personas que clasifiquen diferentes respuestas o las califiquen en una escala. El «equipo rojo», en el que expertos en seguridad intentan comprometer la seguridad del agente, también forma parte de este proceso.
- Enfoques híbridos: no pienses en tus opciones como simples pruebas manuales frente a pruebas automatizadas para agentes de IA: la estrategia más eficaz suele combinar pruebas automatizadas para obtener velocidad y escala con revisiones humanas específicas para obtener información más profunda y juicios matizados.
Garantizar la reproducibilidad
Es fundamental que tus evaluaciones se puedan repetir y sigan produciendo los mismos resultados. Esto significa controlar variables, como el uso de «semillas aleatorias» fijas, y documentar cuidadosamente cómo se configuran el agente y las pruebas. Las evaluaciones reproducibles le ayudan a comparar diferentes versiones de su agente de forma justa, lo que le permite atribuir con confianza los cambios de rendimiento a mejoras o regresiones específicas en su modelo de IA.
La naturaleza no determinista de muchos sistemas de IA generativa, en particular los que utilizan LLM, plantea un reto importante para la reproducibilidad. Sin embargo, al registrar meticulosamente todos los parámetros, entradas y configuraciones del entorno, puede crear una base de referencia fiable. Esta base de referencia garantizará que, cuando observe un cambio en el rendimiento del agente, pueda identificar con confianza si se debe a un cambio en el código, una actualización del modelo o un factor externo. Al final, se preocupará menos por si los cambios en el rendimiento se deben a variaciones aleatorias, lo que hará que el proceso de evaluación del agente de IA sea transparente y fiable.
Proceso iterativo
La evaluación no es algo que se haga una sola vez. Es un ciclo continuo:
- Realice sus pruebas.
- Recopile y cuantifique los resultados utilizando las métricas que haya elegido.
- Analice detenidamente lo que los resultados le dicen sobre los puntos fuertes y débiles de su agente.
- Utilice esta información para mejorar el modelo de su agente, sus indicaciones o su diseño general.
Este bucle constante es fundamental para mejorar su agente de IA con el tiempo.
Prácticas recomendadas para una evaluación eficaz de los agentes de IA
Para sacar el máximo partido a sus esfuerzos de evaluación de agentes de IA, siga estas pautas prácticas. Le ayudarán a garantizar que sus evaluaciones sean informativas y aplicables, lo que se traducirá en mejoras reales en el rendimiento de los agentes.
- Defina criterios de éxito claros: antes de empezar a realizar pruebas, tenga muy claro qué se considera «éxito» para su agente de IA. ¿Qué objetivos específicos debe alcanzar? Establecer estos objetivos le ayudará a diseñar evaluaciones específicas.
- Realice un seguimiento de múltiples métricas y equilibrarlas: evite centrarse únicamente en una única métrica de rendimiento. En su lugar, mida simultáneamente varias métricas de evaluación del agente de IA (como la velocidad, la precisión y la satisfacción del usuario). Esto le proporcionará una visión equilibrada y le ayudará a tomar decisiones más informadas.
- Utilice referencias y comparaciones: compare siempre el rendimiento actual de su agente con un punto de partida (referencia) o con versiones anteriores. Esto le ayudará a determinar si sus cambios están mejorando o empeorando el rendimiento del agente.
- Automatice la evaluación en el flujo de trabajo de desarrollo: integre sus evaluaciones en su proceso de desarrollo habitual, especialmente en sus canalizaciones de CI/CD (integración continua/implementación continua). De esta manera, las pruebas se ejecutan automáticamente con cada nuevo cambio, detectando los problemas de forma temprana.
- Registre datos detallados para la depuración: cuando su agente no funciona como se espera, es fundamental disponer de registros detallados del proceso de evaluación, incluyendo entradas, salidas y pasos intermedios. Estos datos le ayudarán a encontrar y solucionar rápidamente los problemas.
- Incluya comentarios humanos cuando sea apropiado: para aspectos como el tono, la creatividad o la experiencia del usuario, el juicio humano es invaluable. Cree mecanismos para recopilar comentarios de usuarios reales o revisores expertos para obtener una comprensión matizada del rendimiento de su agente.
- Considere la posibilidad de realizar pruebas de robustez/estrés: desafíe intencionadamente a su agente con entradas complejas, inesperadas o incluso maliciosas. Estas «pruebas de estrés» ayudan a garantizar que su agente se mantenga estable y fiable incluso en las condiciones más difíciles.
- Documente y versiona todo: mantenga registros claros de sus configuraciones de evaluación, escenarios de prueba y todos los cambios. Al igual que con el código, la versionado de sus evaluaciones garantiza la transparencia y la reproducibilidad.
- Repita y refine continuamente: la evaluación es un ciclo continuo. Utilice los resultados para orientar las mejoras y, a continuación, vuelva a evaluar. Este bucle continuo garantiza que su agente de IA mejore continuamente y se adapte a los nuevos retos.
Siguiendo estas prácticas recomendadas, puede crear un sistema para evaluar los agentes de IA que impulse constantemente su mejora y garantice una implementación fiable.
Ejemplos del mundo real
Comprender la evaluación de los agentes de IA es más fácil cuando se ve en acción en diferentes tipos de IA. A continuación se muestran algunos ejemplos del mundo real que ilustran cómo se aplican estos principios:
Agentes de atención al cliente (chatbots, asistentes virtuales)
- Qué hacen: estos agentes gestionan las consultas de los clientes, proporcionan asistencia y automatizan las tareas rutinarias.
- Cómo se evalúan: Comprobamos su velocidad de respuesta, la precisión de sus respuestas y la satisfacción general de los usuarios (por ejemplo, ¿se resolvió el problema del cliente de forma rápida y correcta?). Esto incluye examinar aspectos como la eficiencia conversacional (el número de turnos necesarios para resolver un problema).
Agentes de creación de contenido
- Qué hacen: Estos agentes de IA ayudan a generar texto, artículos u otro contenido creativo, a menudo adaptado a necesidades o tendencias específicas.
- Cómo se evalúan: Las métricas clave incluyen la precisión de la información generada, su coherencia (¿tiene sentido y fluye bien?) y su atractivo (¿mantiene la atención del lector o logra su propósito?). También verificamos si hay alucinaciones y si se basan en fuentes fiables.
Agentes de IA/estrategia para videojuegos
- Qué hacen: La IA en los videojuegos, como los oponentes avanzados (por ejemplo, AlphaGo), aprende estrategias y toma decisiones para competir contra los jugadores.
- Cómo se evalúan: Evaluamos su adaptabilidad (qué tan bien aprenden nuevas estrategias), su pensamiento estratégico (¿pueden planificar movimientos complejos?) y su capacidad para aprender con el tiempo y mejorar su rendimiento frente a jugadores humanos u otra IA.
Agentes de automatización de compras en línea/flujos de trabajo
- Qué hacen: Estos agentes automatizan pasos en procesos como las compras en línea, la introducción de datos u otros flujos de trabajo empresariales, a menudo interactuando con diversas herramientas.
- Cómo se evalúan: Las comprobaciones cruciales incluyen la precisión de la llamada a la herramienta (¿el agente selecciona y utiliza las herramientas externas adecuadas?), la eficiencia de la ruta (¿toma los pasos más cortos y lógicos para completar una tarea?) y el manejo de los parámetros (¿pasa correctamente la información entre los pasos o a las herramientas?).
Estos ejemplos ponen de relieve que la evaluación eficaz de los agentes de IA siempre se adapta a la función y al contexto específicos de la IA, lo que garantiza que aporte valor donde más importa.
Resumen
La evaluación de los agentes de IA es un paso complejo pero esencial para crear una IA fiable, eficiente y ética. La combinación de diversas métricas de evaluación de agentes de IA con métodos sólidos de evaluación de agentes de IA es clave para comprender y optimizar verdaderamente las capacidades de su agente de IA. Este proceso continuo de evaluación y perfeccionamiento garantiza que los agentes sigan siendo eficaces, coherentes y fiables a medida que se adaptan a los retos del mundo real.
En QAwerk, nuestro equipo especializado en control de calidad ofrece servicios integrales de pruebas de agentes de IA. Nos aseguramos de que sus agentes de IA sean fiables, funcionen de manera óptima y cumplan con las directrices éticas. Proporcionamos la experiencia necesaria para aprovechar con confianza la IA, impulsando el crecimiento empresarial y reduciendo eficazmente los riesgos asociados. Para garantizar que sus agentes de IA sean de alta calidad y se utilicen de forma responsable, póngase en contacto con nuestros expertos hoy mismo para una consulta.
Preguntas frecuentes
¿Qué es la evaluación de agentes de IA?
La evaluación de agentes de IA es el proceso sistemático de evaluar el rendimiento, la fiabilidad, la seguridad y el cumplimiento de los comportamientos deseados de un agente de IA. Garantiza que el agente funcione de forma eficaz y ética en situaciones reales.
¿Cómo se evalúan los agentes de IA?
Para evaluar los agentes de IA, se definen objetivos claros, se preparan diversos datos de prueba y se utilizan varias estrategias de evaluación. Estas incluyen pruebas de rendimiento automatizadas, evaluaciones con intervención humana y enfoques híbridos. El proceso implica medir continuamente las métricas, analizar los resultados y perfeccionar el agente.
¿Cómo se mide el rendimiento de un agente de IA?
El rendimiento de un agente de IA se mide utilizando una serie de métricas de evaluación de agentes de IA. Estas abarcan aspectos como la tasa de finalización de tareas, la precisión, el tiempo de respuesta, la utilización de recursos, la calidad de los resultados, la solidez y la satisfacción del usuario.
¿Cuáles son las métricas de evaluación de los agentes de IA?
Las métricas clave para evaluar los agentes de IA incluyen la latencia, el rendimiento, el coste por interacción, la tasa de éxito, la precisión, la tasa de alucinaciones, la coherencia, la tasa de error, la detección de sesgos y las puntuaciones de satisfacción del usuario.
¿Cuáles son algunos de los retos comunes en la evaluación de agentes de IA?
Algunos retos comunes en la evaluación de agentes de IA incluyen definir una «verdad fundamental» clara para los resultados subjetivos, gestionar los comportamientos nuevos o inesperados del agente, el coste y la escalabilidad de una evaluación humana exhaustiva, y abordar los posibles sesgos dentro de los propios datos de evaluación.





